Statistical Inference
Parameter estimation
Method of moments
Method of maximum likelihood
Method of Moments
The $k$-th population moment is defined as
The $k$-th sample moment is defined as
estimates $\mu_k$ from a sample $(X_1, \ldots, X_n)$.
The first sample moment is the sample mean $\bar{X}$.
Central Moments
For $k \geq 2$, the $k$-th population central moment is defined as
The $k$-th sample central moment is defined as
estimates $\mu_k$ from a sample $(X_1, \ldots, X_n)$.
Estimation
To estimate $k$ parameters, equate the first $k$ population and sample moments,
The method of moments estimator is the solution of this system of equations.
Example 1
To estimate parameter $\lambda$ of Poisson($\lambda$) distribution.
There is only one unknown parameter, hence we write one equation,
Thus,
Method of Maximum Likelihood
Maximum likelihood estimator is the parameter value that maximizes the likelihood of the observed sample.
For a discrete distribution, we maximize the joint pmf of data $P(X_1, \ldots, X_n)$.
For a continuous distribution, we maximize the joint density $f(X_1, \ldots, X_n)$.
MoML: Discrete Distribution
To maximize this likelihood, we consider the critical points by taking derivatives with respect to all unknown parameters and equating them to 0, $\frac{\partial}{\partial \theta}P(\mathbf{X}) = 0.$
Differentiating the sum
is easier than differentiating the product.
Besides, logarithm is an increasing function, so the likelihood $P(X)$ and the log-likelihood $\ln P(X)$ are maximized by exactly the same parameters.
Example 2
The pmf of Poisson distribution is
Thus, we need to maximize
MoML: Continuous Distribution
In the continuous case, the method of maximum likelihood will maximize the probability of observing âalmostâ the same number.
The probability to observe exactly $X = x$ is 0.
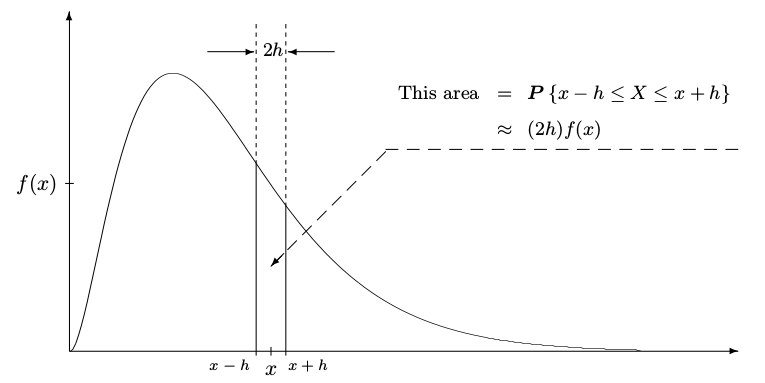
The probability of observing a value close to $x$ is proportional to the density $f(x)$.
Example 3
The pdf of Exponential distribution is
So,
This is the only critical point. The estimator $\hat{\lambda}$ is just the reciprocal of the $\bar{X}$.
Estimation of Standard Errors
In Examples 1 and 2, we found the method of moments and maximum likelihood estimators of the Poisson parameter $\lambda$, $\hat{\lambda} = \bar{X}$
Let us now estimate the $\hat{\lambda}$.
For Poisson: $\sigma = \sqrt \lambda$, so
Estimating $\lambda$ by $\bar{X}$
Confidence Intervals
An interval $[a, b]$ is a $(1-\alpha)100\%$ confidence interval for the parameter $\theta$ if it contains the parameter with probability $(1 -\alpha)$,
Coverage probability $(1 -\alpha)$ is also called a confidence level.
Construction of CI
a) Assume there is an unbiased estimator $\hat{\theta}$ that has a Normal distribution.
b) Standardize it,
c) $Z$ falls between the Standard Normal quantiles $q_{\alpha/2}$ and $q_{1-\alpha/2}$ with probability $(1 -\alpha)$, denoted by
Construction of CI (cont.)
d) Then,
e) Substituting,
such that
Margin of Error: Certainty vs. Precision
The extent of that interval on either side of is called the margin of error (ME). The general confidence interval can now be expressed in terms of the ME.
The more confident we want to be, the larger the margin of error must be.
Every confidence interval is a balance between certainty and precision.
Example 4
In March 2010, a Gallop Poll found that 1012 out of 2976 respondents thought economic conditions were getting better – a sample proportion of
We’d like use this sample proportion to say something about what proportion, $p$, of the entire population thinks the economic conditions are getting better.
Confidence Interval for Proportions
We know that our sampling distribution model is centered at the true proportion
So, following CLT, we can aproximate the sampling distribution with Normal, and use $\hat{p}$ to calculate standard error, SE.
Example 4 (cont.)
Because the distribution is Normal, we expect that about 95% of all samples of 2976 U.S. adults would have had sample proportions within two SEs of $p$, 0.0018.
"It is probably true that 34.0% of all U.S. adults thought the economy was improving."
We can be pretty certain that whatever the true proportion is, it’s probably not exactly 34.0%.
"We don't know the exact proportion of U.S. adults who thought the economy was improving but the interval from 32.2% to 35.8% probably contains the true proportion."
This is close to correct, but what is meant by probably?
Example 4 (cont.)
An appropriate interpretation of our confidence interval would be,
"We are 95% confident that between 32.2% to 35.8% of U.S. adults thought the economy was improving."
The confidence interval calculated and interpreted here is an example of a one-proportion z-interval.
Critical Values
For any confidence level the number of SEs we must stretch out on either side of $\hat{\theta}$ is called the critical value.
Because a critical value is based on the Normal model, we denote it $z^*$.
| CI | $z^*$ |
|---|---|
| 90% | 1.645 |
| 95% | 1.960 |
| 99% | 2.576 |
Example 5
In the spring of 2009 workers at Sony France protesting layoffs, took the boss hostage, "bossnapping". What did other French adults think of this practice? Where they sympathetic? Understanding? Approving?
A polls taken in April 2009 found:
30% “approving”,
63% were “understanding” or “sympathetic” of the action,
Only 7% condemned the practice of "bossnapping"
The poll was based on a random representative sample of 1010 adults.
Example 5 (cont.)
Conditions:
Randomization Condition: The sample was selected randomly.
10% Condition: The sample is certainly less than 10% of the population.
Success/Failure Condition:
The conditions are satisfied so a one-proportion z-interval using the Normal model is appropriate.
Example 5 (cont.)
What can we conclude about the proportion of all French adults who sympathize?
For a 95% CI, $z^* = 1.96$, so
or
Based on the survey we can be 95% confident that between 60.1% and 65.9% of all French adults were sympathetic.
Choosing the Sample Size
To get a narrower confidence interval without giving up confidence, we must choose a larger sample.
Thus,
or
Example 6
Suppose a company wants to offer a new service and wants to estimate, to within 3%, the proportion of customers who are likely to purchase this new service with 95% confidence. How large a sample do they need?
We proceed by guessing the worst case scenario for $\hat{p}$. We guess $\hat{p}$ is 0.50 because this makes the SD (and therefore n) the largest.
We can conclude that the company will need at least 1068 respondents to keep the margin of error as small as 3% with confidence level 95%.
Confidence Intervals for Means
CI for the Population Mean
Let us construct a confidence interval for the population mean $\theta = E(X) = \mu $
It's estimator is $\hat{\theta} = \bar{X}$,
If a sample $X$ comes from Normal distribution, then $\bar{X}$ is also Normal and we proceed with construction of CI.
If a sample comes from any distribution, but the sample size $n$ is large, then $\bar{X}$ approximately Normal distribution according to CLT, and we proceed with construction of CI.
So for the population mean and known $\sigma$, $\sigma(\hat{\theta}) = \sigma/ \sqrt{n}$ $CI = \bar{X} \pm z_{\alpha/2}\frac{\sigma}{\sqrt n}$
CI for for Two Means Difference
To construct a confidence interval for the difference between population means, $\theta = \mu_X - \mu_Y$.
Propose an estimator of $\theta$, $\hat{\theta} = \bar{X} - \bar{Y}$
Check that $\hat{\theta}$ is unbiased.
Check that $\hat{\theta}$ is a Normal or approximately Normal distribution.
Find the standard error of $\hat{\theta}$ (using independence)
The Sampling Distribution for the Mean
Because the true value of the population standard deviation $\sigma$ is unknown.
Instead of $\sigma$, we will use $s$, the sample standard deviation from the data. So,
Confidence intervals means will be
where the $ME$ was equal to a critical value, $z^*$, times standard error $\sigma(\bar{\theta})$.
Gosset's t
William S. Gosset discovered above when he used the standard error $\frac{s}{\sqrt n}$ the shape of the curve was no longer Normal.
New model was called the Student's t, and it is always bell-shaped, but the details change with the sample sizes.
The Student's t-models form a family of related distributions depending on a parameter known as degrees of freedom.
Example 7
Data from a survey of 25 randomly selected customers found a mean age of 31.84 years and the standard deviation was 9.84 years.
What is the standard error of the mean?
How would the standard error change if the sample size had been 100 instead of 25? (Assume that $s$ = 9.84 years.)
Practical sampling distribution model for means
When unknown standard error of $\bar{\theta}$ is replaced by its estimator
The standardized sample mean,
no longer has a Normal distribution!
We need to use a Student's $t$-distribution with $n-1$ degrees of freedom.
One-sample t-interval
When the assumptions and conditions are met, the confidence interval for the population mean, $\mu$ is:
The critical value $t^*_{n-1}$ depends on the particular confidence level, $\alpha$, that you specify and on the number of degrees of freedom, $n-1$, which we get from the sample size.
Finding t-values
For example, suppose we’ve performed a one-sample t-test with 19 df and a critical value of 1.639, and we want the upper tail P-value.
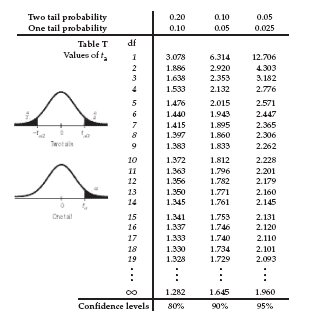
From the table, we see that 1.639 falls between 1.328 and 1.729. All we can say is that the P-value lies between P-values of these two critical values, so 0.05 < P < 0.10.
Example 8
Data from a survey of 25 randomly selected customers found a mean age of 31.84 years and the standard deviation was 9.84 years.
Construct a 95% confidence interval for the mean. Interpret the interval.
Example 8 (cont.)
Construct a 95% confidence interval for the mean.
Interpret the interval.
We're 95% confident the true mean age of all customers is between 27.78 and 35.90 years.
Assumptions and Conditions
Independence Assumption: There is no way to check independence of the data, but we should think about whether the assumption is reasonable.
Randomization Condition: The data arise from a random sample or suitably randomized experiment.
10% Condition: The sample size should be no more than 10% of the population. For means our samples generally are, so this condition will only be a problem if our population is small.
Nearly Normal Condition: The data come from a distribution that is unimodal and symmetric. This can be checked by making a histogram.
Normal Population Assumption
For very small samples (n < 15), the data should follow a Normal model very closely. If there are outliers or strong skewness, t-methods shouldn’t be used.
For moderate sample sizes (n between 15 and 40), t-methods will work well as long as the data are unimodal and reasonably symmetric.
For sample sizes larger than 40 or 50, t-methods are safe to use unless the data are extremely skewed. If outliers are present, analyses can be performed twice, with the outliers and without.
Example 9
In 25 randomly selected customers survey found a mean age of 31.84 years and the standard deviation was 9.84 years. A 95% confidence interval for the mean is (27.78, 25.90).
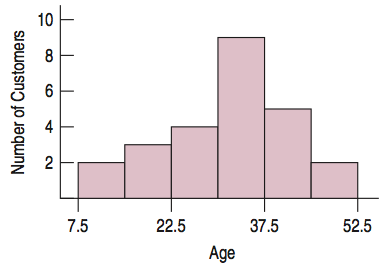
Independence: Data were gathered from a random sample and should be independent.
10% Condition: These customers are fewer than 10% of the customer population.
Nearly Normal: The histogram is unimodal and approximately symmetric.